Archivemimaticaは、デフォルトでOCR認識用としてTesseractを使っています。基本は英語認識になっているので、日本語を認識できるようにしてみましょう!
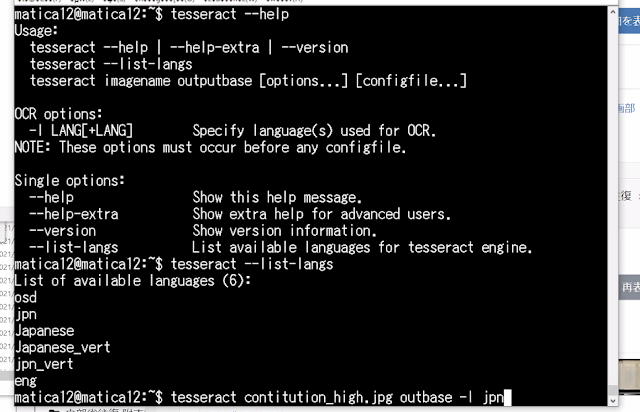
Tesseractのファイルは、/usr/share/tesseract-ocr/ の下に実行ファイルがあります。まずは、そこをみてましょう。

各ファイルは以下のように関係しています。
jpn.traineddata:日本語
jpn_vert.traineddata:日本語(縦書き)
Japanese.traineddata:日本語
eng.traineddata:英語
osd.traineddata:文字の方向の判定ここで日本語と英語のファイルをちょっといじってみます。Archivematicaでは英語だけを処理するように設定されているので、こっそりeng.traineddataの中身をjpn.traineddataにすり替えてテストしてみます。とりあえず、元のデータがなくなるとまずいので、eng.traineddata.originalにしておきます。

次に、eng.traineddataの中身をjpn.traineddataに入れ替えます。

このあと、Archivematicaに日本語文書のJPGファイルを入れてingestしてみます。
以下の画像をingestしました。

ingestしたJPGファイル
Transcriptionのマイクロサービスでは、Yesを選んでください。
結果は〜〜〜以下のように日本語を認識してくれました!

OCR認識で出力された結果
師匠ありがとうございます!これでTesseractの仕組みが少し理解できました!
今度は、ArchivematicaのPreservation planning からcommandを変更してみましょう。どちらかというとこちらが正式な方法です。先いじったファイルは元の状態に戻してから試してください。
Preservation planningでは、コマンドやルールの変更・追加ができます。マイクロサービスで行われる処理の中で正規化(Normalization)のようにルールが必要なタスクについては、行う処理内容をコマンドで書いて、実行する対象と結びつけます。これが、ルールというわけですね。
OCRの処理はTranscriptionのマイクロサービスで行われますので、TranscriptionのCommandを変更してみます。
以下が、Transcriptionのコマンドを変更する画面です。

上記のCommandの最後に -l jpn を追記しました。languageをjpnにしてくださいというコマンドです。試した結果……成功しました!(^^)/

上記のCommandの最後に -l jpn を追記しました。languageをjpnにしてくださいというコマンドです。試した結果……成功しました!(^^)/
では、次は縦書きも試してみます。
今度は以下のコマンドを最後に入れてみます。
-l jpn +Japanese_vert
これも成功しましたが、縦書きの認識率は少し低いです。でも7割程度は認識しているように見えます。
日本語関係の学習ファイルが2つあったので、以下でも試してみます。
-l Japanese +Japanese_vert
そうすると、以下のように結果が少し異なりました。

左:jpn 右:Japanese
Japanese.traineddataの場合は日本語と英語の学習用テキストを混在した状態で学習させた代物ということらしいです。また、出力結果に余計な空白が含まれる問題があるとのことです。(それで右のJapaneseで試した結果がああなったわけね…)
参考サイト
今日はここまでです!
今日は意外と順調に進みました。いつもこうだといいですね〜〜
================================
10月8日(金)19:00〜
やることは後日連絡です。ではまたね〜