風が強くて華奢な女子大生は飛ばされるのではないかと思える天気でしたが、横に増えつつある中年女性は飛ばされる心配もなく、無事道場に着きました。(@^^@)
ですが、今日は参加者が少ない。(皆どうしたんだよ〜〜)
でも、いつものようにガソリンを入れて始めます!
皆を待ちながらしばし議論〜
archivemeticaからAtoMまでの流れを今一度説明するYo!
(ホワイトボードに何か書くYo!)
やはり、exportした時のLegacy IDは、データ更新のときにはあまり気にしないで、もとのLegacy IDを管理するのが正しいのではという話をしました。
そうすると…
DIPにはLegacy IDがない。どうするんだ?
これがずっと前から悩んでいた問題でした。
さてさて、いつものように結論はなし!
問題を再確認したところで次に進みます。
===============================
今日は久しぶりにArchivemeticaからDIPを作ります!
久しぶりなので、やはりエラーがでました。
我々の期待を裏切らない機械です。
でもなんとかDIPをAtoMに入れました。
そのCSVをexportします。
Legacy IDが付与されて出てきましたが、このLegacy IDを利用して
記述をupdateすると新しくデータが登録されてしまいます。
だから〜DIPで入れたもののLegacy IDを確認するしかないってこと?
(これは面倒だ・・・)
少し紛らわしいので、ここでは元のLegacyIDを元(もと)ちゃん、export時に出てくるLegacy IDを偽ちゃんと呼ぶことにしましょう。
ここで、カッコいいエンジニアの出番です! シャキ─(σ`・∀・´)σ
コマンドモードから、keymapテーブルを探し、その中身を確認します。
そこには、source_id, target_id, source_nameが記録されています。
なんと!keymapテーブルでは、偽ちゃんがtarget_idになっていて、それに対応するsource_id(これが元ちゃん)が確認できました。DIPで入れたものでも、元ちゃんが存在するのです。updateに使うLegacy IDは、もちろんここにある元ちゃんということになるのでしょうか。
ではでは、確認した元ちゃんをCSVのLegacy IDとして入力し、タイトルだけを変えてみます。そしてupdate~~~
そうすると、なんとうまくupdateされました!
(ここまでの道のりは長かった… ITに弱い人間が生きていくのは大変です…)
ここでもう一つ発見!
偽ちゃんは意味のないように思えましたし、なぜそんなものが出てくるのか、ずっと疑問でした。まぎらわしいし、なぜそんなことをする必要があるのか…
予想ではありますが、この偽ちゃんを利用するれば、大量のデータを更新できそうな気がしました。つまり、CSVの偽ちゃんに対応する元ちゃんを探して、自動で入れ替えるプログラムを組めば、機械で処理ができます。
また、色々実験した結果、元ちゃんとsource_nameは重複して存在し得ることがわかりました。しかし、target_idは重複しません。なのでtarget_idがデータベース上で、唯一の識別idとして機能しているのはと思われます。
色々実験した結果、元ちゃんと偽ちゃんに関する理解は少し深まりました。
道場での実験に加えて、メンバーによる個別実験が行われました。
これについては以下の記事を参考にしてください。
https://irisawadojo.blogspot.com/2018/08/atomcsv.html
http://irisawadojo.blogspot.com/2018/07/atomcsvupdate.html
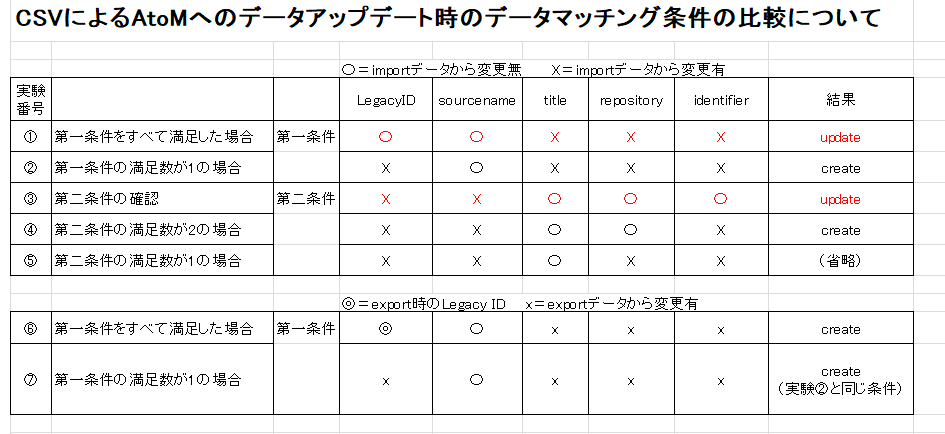
最終的に、わかったことを以下簡単に整理します。
- KeymapにはLegacy IDがsource_idとして登録される。
- 親子関係が変わっても、source_idとtarget_idは変わらない。
- Legacy IDは重複し得る。
- まったく同じファイルを2回登録すると、target_idのみ異なる。
- まったく同じファイルを登録した場合は、最新のものが更新される。
- Legacy IDが重複した場合、source nameが一致するもののみアップデートされる。
- CSV export時のLegacy ID(kepmapテーブルにおけるtarget_idは更新時のマッチング判定にはつかわれなさそう。(ほかに、Legacy IDが異なるが同じものであることの判定や、Legacy IDとsource_nameが同一であるが異なるものであることの判定などに使われている?)
今日は通常より短めの作業でしたが、一歩進みましたので良い気分で終わります!
========================
皆気分がよくて、次回やること話すの忘れました。(^^;)